author: Shuo Zhang
My goal in this project is to analyze user data (and other relevant data) pulled through the Last.fm API to improve our understanding/evaluation of the effectiveness of the current music recommendation algorithm, and to use that knowledge to build better recommendation product. Concretely, for example, can we predict whether a user will love an artist, given that s/he already loves another similar artist (similarity according to the Last.fm artist similarity algorithm), and by analyzing the relevant data of the user's listening history, tags, artists, albums, tracks, bio, etc.?
For this demo, I have extracted two pilot data sets from the Last.fm using its API. These include the list of 50 top artists for each user in 2000 users (this number can be much larger in the later stages of this project), and a list of the top 100 similar artists for each of the more than 25000 unique artists included in the first data set (with 2000*50=100,000 artists in total). The list of 2000 users are extracted using one seed user and a list of 50 of the user's friends, by traversing the user's friends trees resursively.
For each user, I have written an algorithm for computing a total-artist-similarity(TAS) score for its 50 top artists (data extracted using Last.fm API, most recent data) by looking into a dictionary built by myself, from the top 100 most similar artists to each of the 50 artist (data also extracted from Last.fm API, for the most recent data). Therefore, if a user has a high TAS score, this means that his/her top 50 artists have high similarity among them, and it in turn would imply that s/he has a rather narrow music taste, not very diverse. And vice versa. The plots created from these two data sets can be seen as a characterization of a users top artists (for about 1600 users). Given a typical user, how likely is it that s/he will favor artists with high or low similarity? how do we know this (infer his taste)? And how does the TAS score distribution look like for a sample of 1600 users? Does it imply the effectiveness of recommending music based on current method of computing artist similarity?
Note: the total similarity score or TAS is an analytical measure / statistic I created here for this particular analysis. It is not a standard measure drawn from the field of Music Information Retrieval (MIR) or user recommendation.
The code used to extract the data sets from the Last.fm API, and the code used to generate the plots below are both located at https://github.com/zangsir/DSAPI. (along with the data set used for generating the plots below). Note that the initial user list is 1997 users, however, after preprocessing and clearning, I am only able to use about 1600 users in the analysis below.
note: Due to the time constraints on carrying out this data collection, and the immense computational complexity involved in retrieving data in this task, I have not been able to extract data of larger size during this challenge, which will be carried out as the project progresses. (For instance, instead of retrieving data on the top 100 similar artists for each of the ~25000 unique artists in this data, I only retrieved the top 20 similar artists, after stopping retrieving top 100 similar artists at about 9000 artists out of 25000 due to its time complexity).
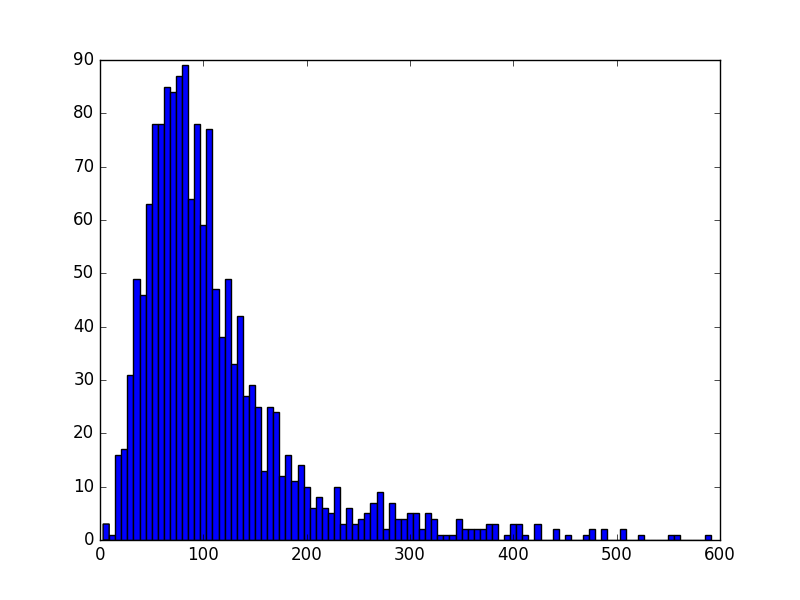
Figure 1: histogram of ~1600 users top 20 artists' similarity score from Last.fm, x-axis: similarity score, y-axis: counts. The top artists' similarity score for a user captures the similarity among the users' most listened artists.
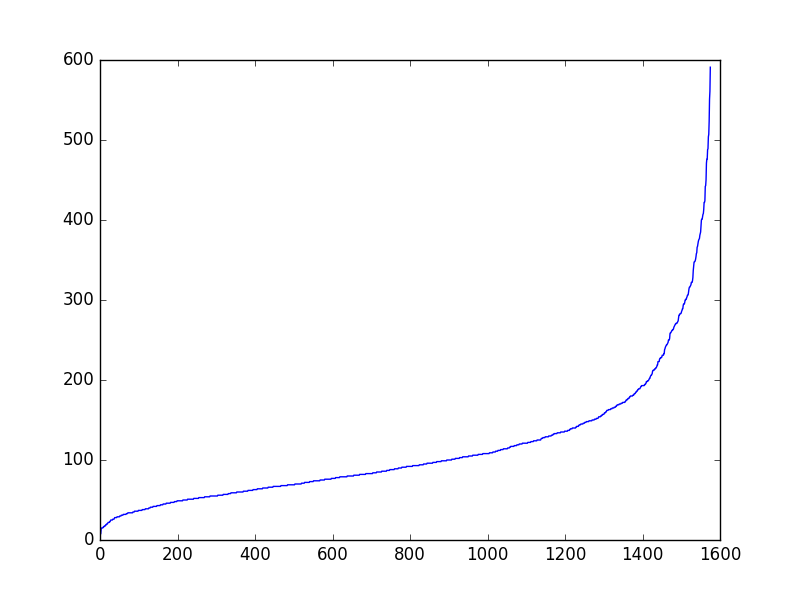
Figure 2: sorted artist similarity score for 1600 users, x-axis: user index sorted, y-axis: similarity score.
These plots characterizes the distribution and range of 1600 users' top artists similarity score. It shows that relatively few users have very narrow range of musical tastes (i.e, their top artists are very similar), while most users display a range of musical tastes. This is the initial clue that the data gives that could make us think of better way of doing music recommendation based on the current algorithm of computing artist similarity and beyond. Figure 2 puts this in a different perspective and shows this trend. It is yet to be analyzed with more measures and more data as this project progresses.